Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

By A Mystery Man Writer

PDF] Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks

Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors

Chips, Free Full-Text
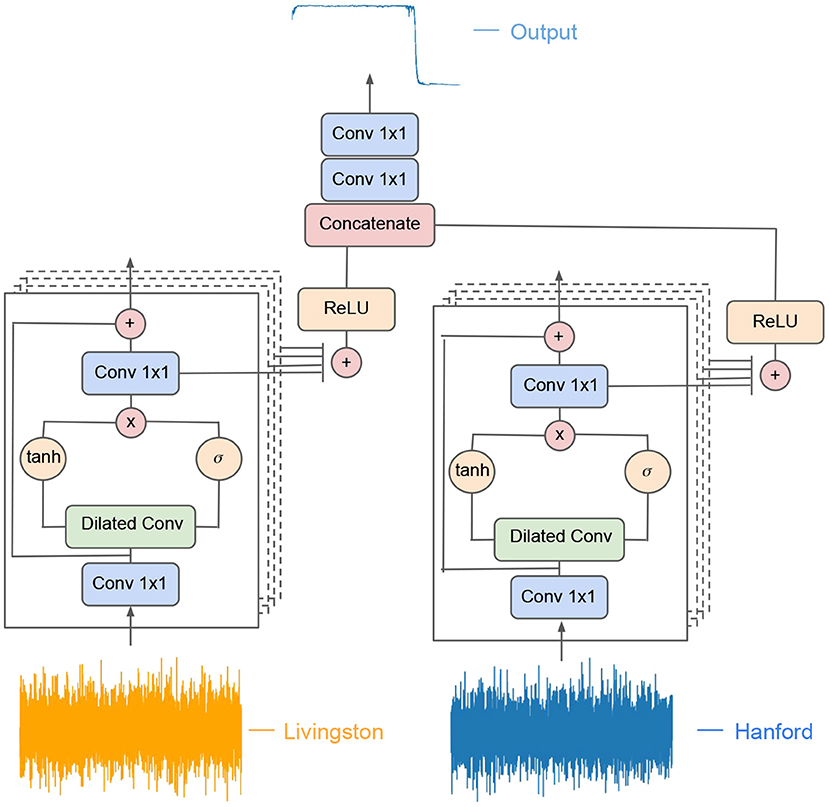
Frontiers Inference-Optimized AI and High Performance Computing for Gravitational Wave Detection at Scale
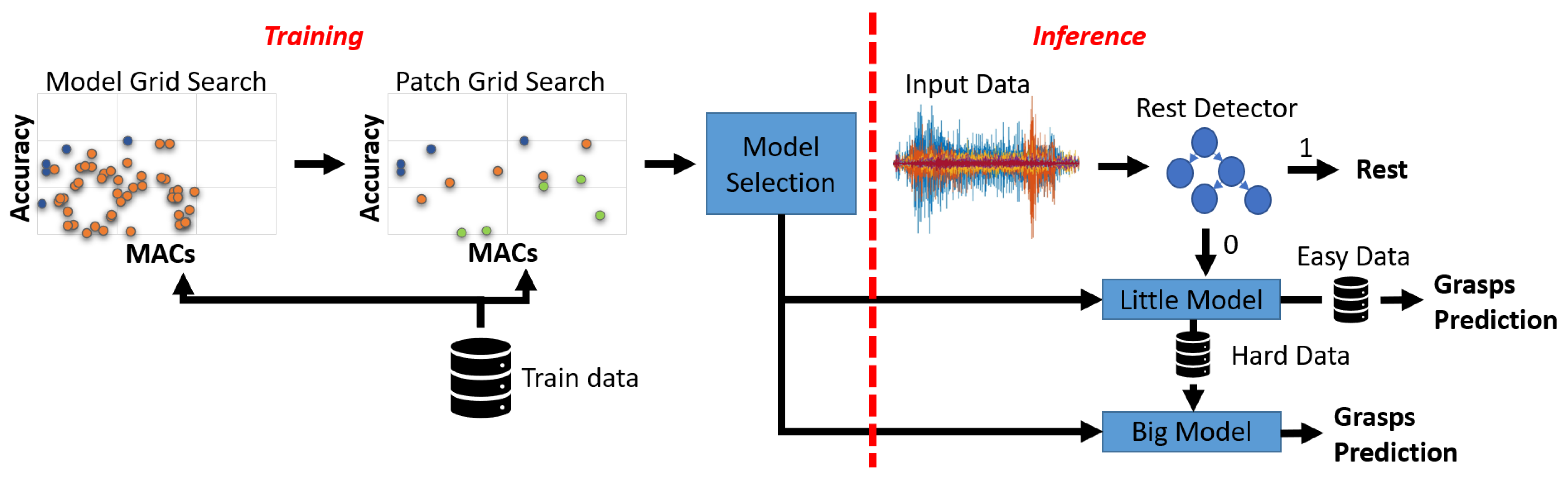
Sensors, Free Full-Text
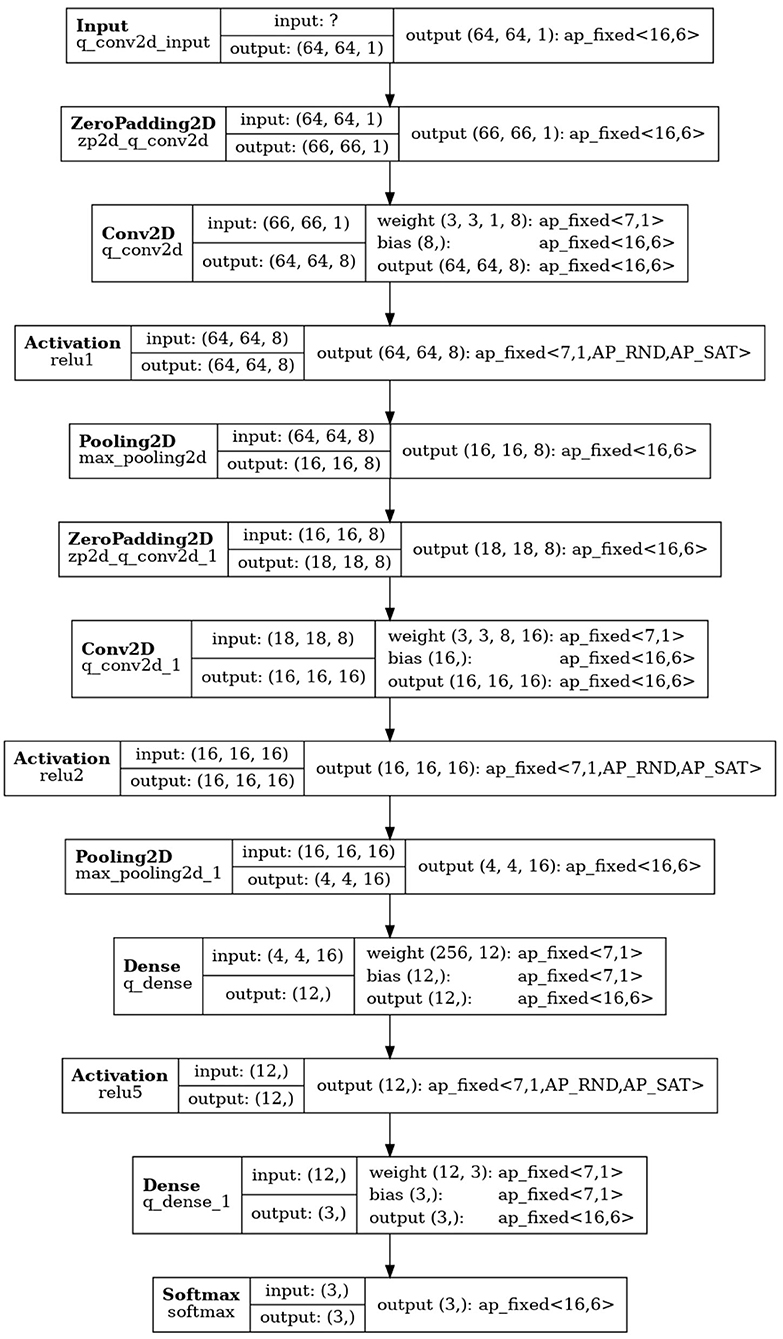
Frontiers Real-Time Inference With 2D Convolutional Neural Networks on Field Programmable Gate Arrays for High-Rate Particle Imaging Detectors

Machine Learning Systems - 10 Model Optimizations
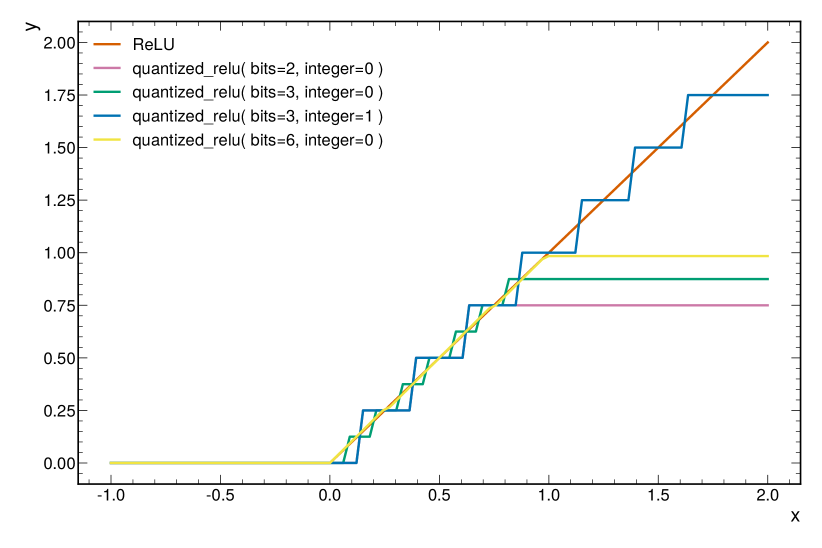
2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors

Enabling Power-Efficient AI Through Quantization

Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference
Machine Learning Systems - 10 Model Optimizations
- 32 Best B Movies That Are Actually Certified Classics

- Exponent Rules Law And Example Teaching math strategies, Teaching math, Math quotes

- Selina Solutions Concise Mathematics Class 6 Chapter 32 Perimeter and Area of Plane Figures download PDF

- Hong Kong Models 1:32 B-17G Flying Fortress (HKM-01E04) Build

- The Strange Saga of the B-32 Dominator





