Tuesday, Oct 01 2024
Language models might be able to self-correct biases—if you ask them

By A Mystery Man Writer
A study from AI lab Anthropic shows how simple natural-language instructions can steer large language models to produce less toxic content.

Articles by Tammy Xu MIT Technology Review

A.I. Is Mastering Language. Should We Trust What It Says? - The New York Times
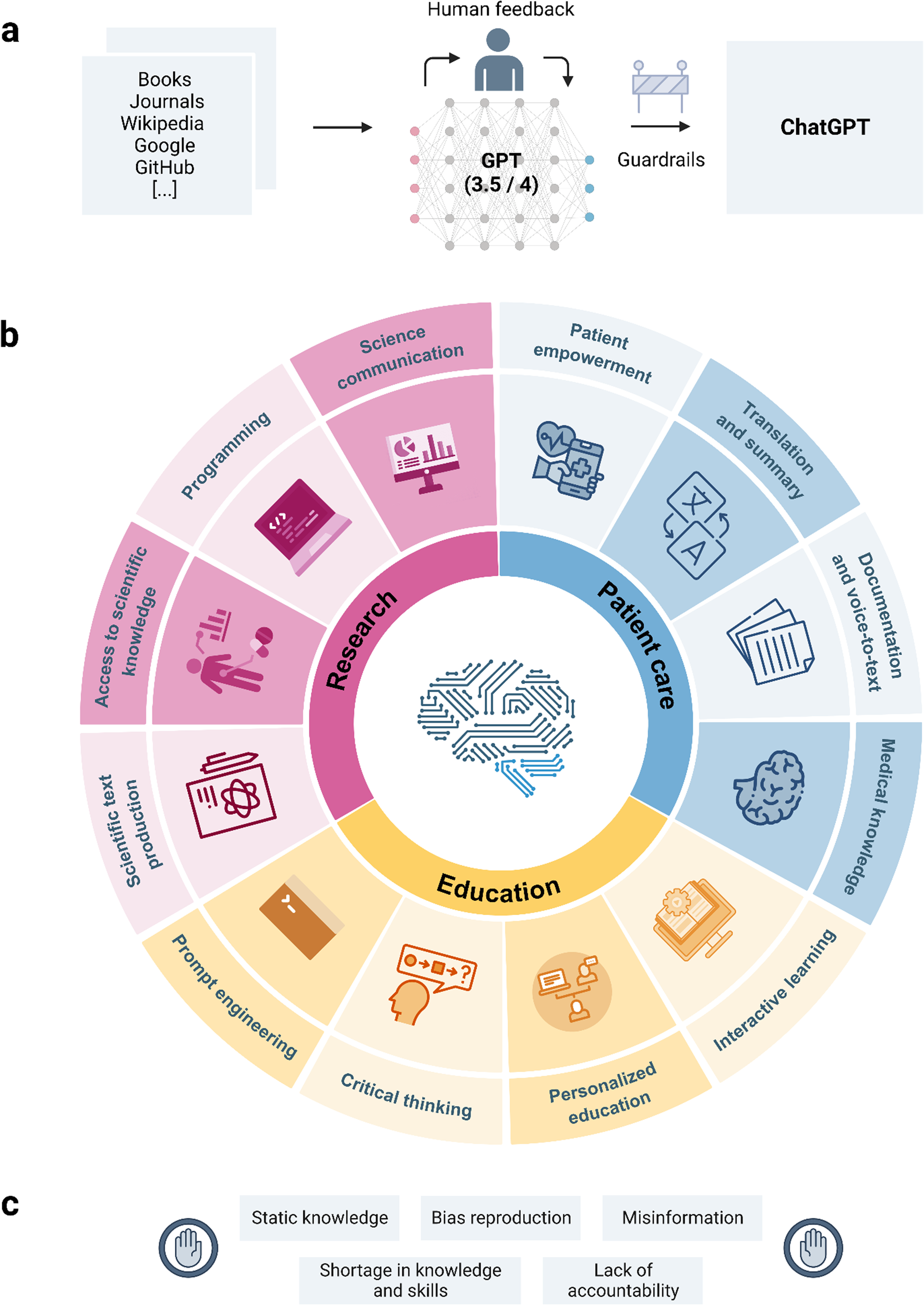
The future landscape of large language models in medicine

Cognitive bias - Wikipedia

Anthropic - Research Scientist, Societal Impacts

Research Scientist, Societal Impacts - Anthropic

Anthropic - Research Scientist, Societal Impacts

Articles by Clive Thompson
/cdn.vox-cdn.com/uploads/chorus_image/image/70765625/ai_bias_board_1.0.jpg)
AI bias: Why fair artificial intelligence is so hard to make - Vox

Articles by A.W. Ohlheiser
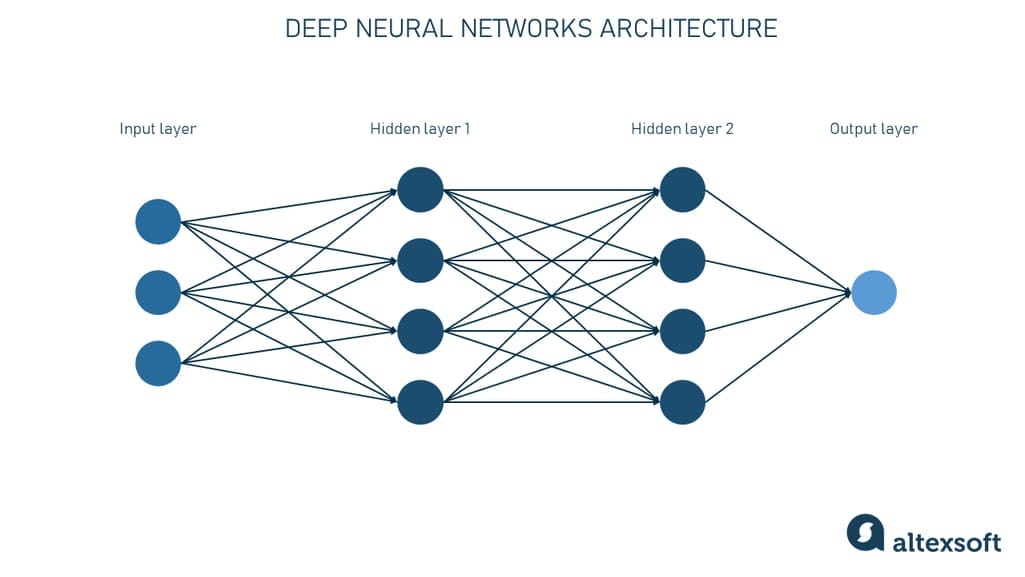
Language Models Explained
Related searches
- DIY Home Mold Test Kit Review

- Mold Armor Do It Yourself Mold Test Kit, Test Surface Mold, Air Quality, and HVAC, Safe and Easy to Use, DIY at Home Mold Kit, Effective Both Indoors

- Defense Cat Dog Heart or Unicorn Mold Shiny Silicone / Fantasy

- Do-it-yourself Mold Remediation: 3 Steps For Your House Clean-up

- a) Fabrication procedure of the PDMS soft mold from the Si master

Related searches
- Buy Cacique Lane Bryant Satin French Cut Mesh Plus Size Bra Full Coverage 40F Online at desertcartZimbabwe

- Boy Shorts Underwear for Women, (5 Pack) of Soft Cotton Panties

- Drops Belle 24 Sand - Winnie's Craft Cafe

- Vafful Women's Sexy Sleeveless Racer Back Halter Neck Tank Tops Bodysuit Black S-XL

- Fajas Shape Body, Lace Butt Lift Shapewear

©2016-2024, slotxogame24hr.com, Inc. or its affiliates